Here is a common scenario — a huge, multi-year project is finally completed, the product is shipped, and the team moves on to a new project or new version. Months or years later, a problem comes up that has been solved before, and one unlucky engineering team is tasked with finding a solution embedded in the old project’s files. Is it possible?
Normally, when a document is needed, the user first searches the PLM system with the presumed engineer’s name and has to guess which project might contain the searched document. Since a PLM is built around a database, this works very well for structured data that might have a field with the project number or other identifying information. But it’s very inefficient on unstructured data, which may or may not contain searchable information.
Which brings us back to our poor engineering team, still browsing a file system and manually scanning for files with that project number. In large enterprises, this can be a gargantuan sorting task involving tens of thousands of files across multiple locations on the network. Then the reality sets in for the engineers: Is it faster to just recreate the data from scratch?
With a data access platform like Aureum installed, finding even decades-old data gets much easier. When disparate data is virtually placed on the same “data plane,” engineers can use threaded search to quickly find simulation, geometry, telemetry and seismic data that might have previously gone dark and would have to be recomputed.
Whenever a file is saved, Aureum indexes it so it can be found far into the future. Both indexing and searching are very efficient because they are distributed: each data node independently indexes the files it stores. When Peaxy Find performs a search, it is sent to all data nodes, which process the query in parallel and send the scored result to the management module, which aggregates the individual results to a system-wide result.
The distributed nature of the query isn’t seen by the user except in how speedy she gets a return. This UML activity diagram show how a query is processed:
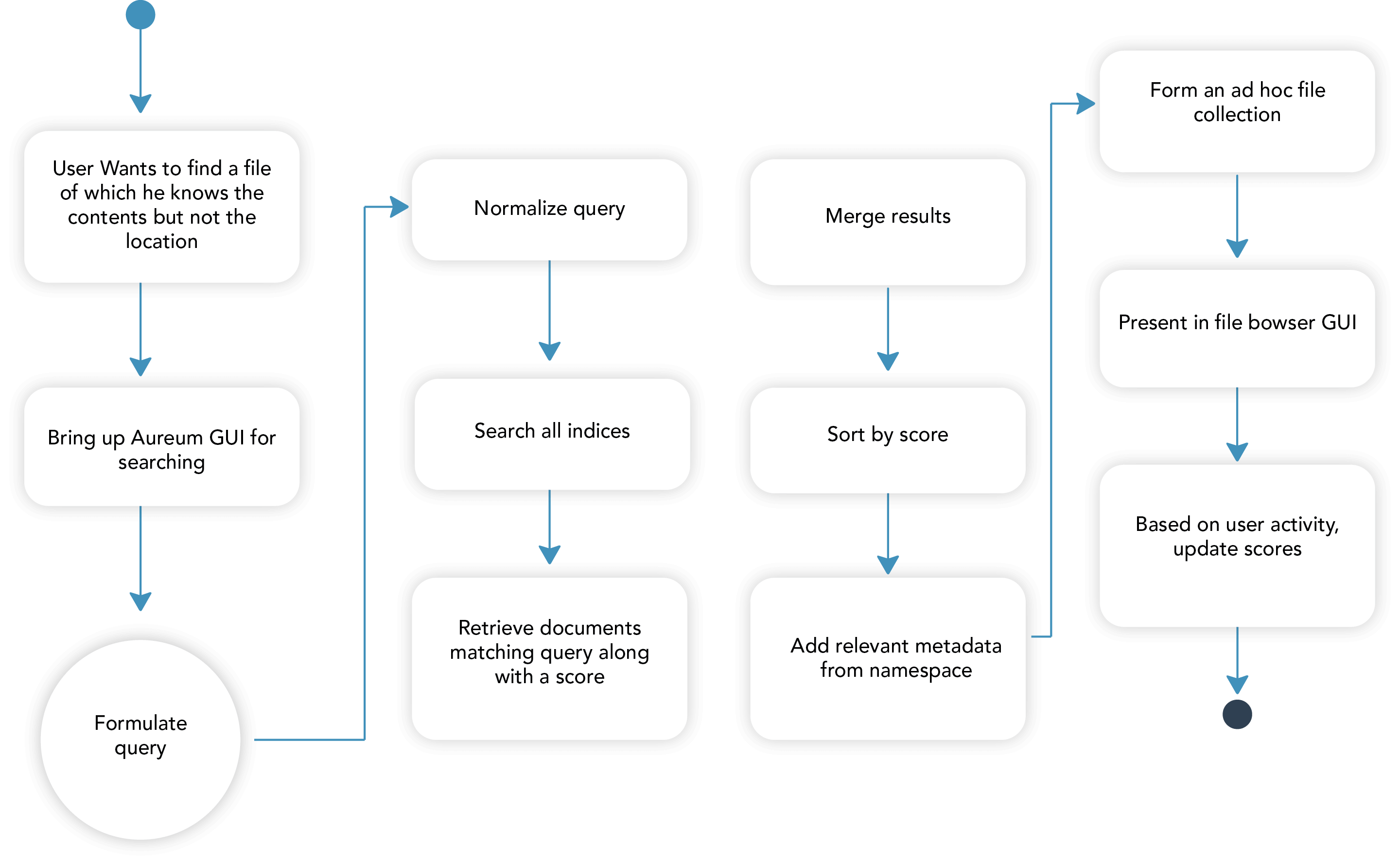
In addition to the usual file formats — TXT, ISO 32000 PDF, and the Microsoft Office DOCX, PPTX, and XLSX formats (excluding email) — Peaxy’s distributed implementation also indexes the popular CAD file formats DXF and DWG. Information in the masthead or title block is indexed, along with any part numbers in the drawing, like you might see on the Bill of Materials (BOM). Other numerical data, geometric data and numbers in embedded spreadsheets are ignored because they clog indices and are never searched for.
Since Aureum is a distributed system and Peaxy Find is optimized for unstructured data, searching is much faster than in a PLM system. In Aureum, all data nodes execute a search in parallel using their smaller local indices instead of having to plow through a PLM system’s large, centralized. Engineers around the world will breathe a sigh of relief now that they no longer have to regenerate every file lost to the dark data black hole.
