
As organizations scale their use of AI and machine learning, preparing data pipelines for anomaly detection has become a foundational requirement for operational reliability, safety, and real-time decision support. Anomaly detection models are only as strong as the data they receive. Without clean, structured, and context-rich pipelines, even the most advanced algorithms will struggle to identify meaningful deviations in system behavior. By investing in robust data preparation practices, teams can dramatically improve model accuracy and reduce false positives, allowing analytics to detect issues long before they become costly failures.
Why Data Quality Matters More Than the Model
An anomaly detection model’s performance depends heavily on the consistency, completeness, and integrity of the data flowing into it. Before training or deploying any model, operators must ensure that their data sources reliably capture the right metrics, at the right frequency, and in formats suitable for downstream processing. Poor quality data can cause models to misinterpret routine variability as anomalies or, worse, miss critical events entirely.
A sound preparation strategy includes:
- Verifying timestamp accuracy
- Validating the range and units of measurements
- Resolving missing values
- Harmonizing data formats across different sensors or systems
This foundational work makes the entire pipeline far more resilient as datasets grow.
Building Strong Data Pipelines for Anomaly Detection
Modern anomaly detection relies on pipelines that can handle structured, semi-structured, and unstructured data from multiple systems. The most effective pipelines share several characteristics. Namely, they automate data ingestion, validate data integrity in real time, enrich raw inputs with meaningful context, and ensure the resulting datasets are time-aligned. These steps allow AI-driven tools to identify subtle deviations that may signal equipment faults, cybersecurity risks, or operational inefficiencies.
Preparing these pipelines requires thoughtful orchestration. Each stage—collection, cleaning, transformation, storage, and model delivery—must follow a consistent schema so downstream models do not need to compensate for inconsistencies. As systems grow more complex and distributed, this becomes increasingly important for scalability.
Key Steps for Preparing Pipelines for Reliable Anomaly Detection
Before a single algorithm is deployed, it’s essential to establish a repeatable framework for data management. The data ingestion process must account for variations in sensor behavior, communication delays, and system-specific quirks. Ensuring that every input is transformed into a standardized format reduces uncertainty and stabilizes model behavior.
Enrichment adds another layer of value. Metadata such as operating mode, asset ID, or environmental conditions allows anomaly detection models to differentiate between expected fluctuations and genuine signs of trouble. Time alignment ensures that data arriving from different sources can be compared accurately, enabling models to evaluate relationships between variables.
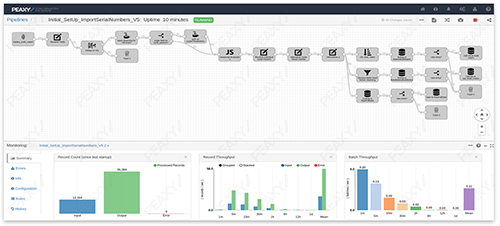
In this visual representation of a Peaxy data pipeline, several transformations are performed on source data before writing it into one of two destination databases.
Storage, Governance, and Access Control
Data pipelines for anomaly detection must also consider where information is stored and how teams will access it. High-frequency, high-volume data streams typically require time-series databases or cloud storage solutions optimized for rapid querying. Strong governance practices—including versioning, retention policies, and access controls—ensure that data remains auditable and secure, particularly in regulated environments.
Consistent governance also improves trust in the output of anomaly detection models. When datasets are well-managed, teams can validate how conclusions were reached, accelerate root-cause analysis, and refine models with confidence.
Enhancing Model Performance with Real-Time Processing
In many applications, anomaly detection is most valuable when insights arrive instantly. Real-time processing frameworks help pipelines handle streaming data, apply transformations on the fly, and push results to dashboards or alerting systems without delay. These capabilities make it possible to detect issues such as thermal runaways, voltage instability, network intrusions, or unexpected process deviations as soon as they occur.
Real-time pipelines must be carefully monitored to ensure they can tolerate fluctuations in data volume or connectivity. Buffering, load balancing, and fault-tolerant architecture help stabilize model performance even during peak demand.
Scaling Pipelines Across More Assets and Use Cases
As organizations expand their monitoring of critical assets and infrastructure, scalability becomes a defining factor. Pipelines must accommodate new data sources with minimal reconfiguration, retain consistent formatting rules, and integrate with analytics platforms that support large, distributed teams. A unified data model allows anomaly detection to scale without introducing inconsistencies between assets or locations.
Over time, scaling well-designed data pipelines results in more accurate models, shorter deployment cycles, and greater organizational trust in AI-driven insights.
Frequently Asked Questions
Why are data pipelines important for anomaly detection?
Data pipelines ensure that models receive high-quality, consistent, and complete information. Without stable pipelines, anomaly detection systems produce unreliable results and may trigger false alarms.
How does data enrichment improve anomaly detection?
By adding context—such as environmental conditions or asset status—models can differentiate between normal variability and true anomalies, reducing unnecessary alerts.
What kinds of data do anomaly detection pipelines handle?
They typically manage time-series sensor data, operational logs, structured system metrics, and unstructured events or messages from a variety of sources.
Can anomaly detection work in real time?
Yes. With real-time processing, pipelines can detect critical anomalies instantly, enabling faster response and preventing safety risks or system failures.
What challenges arise when scaling data pipelines?
Common issues include inconsistent data formats, delayed ingestion, storage bottlenecks, and complexity integrating new assets—challenges that unified schema design and strong governance can resolve.